
AI Labor Trafficking Detection Tool: A New Resource
Rusmiya Aqid is a student at Lexington High School who built a labor trafficking detection tool with Dr. Clayton Greenberg, a mentor at Inspirit AI.
Research from the National Institute of Justice shows that human trafficking is a topic that is both underreported and under prosecuted in comparison to other crimes. Quantitative data on trafficking is limited. Namely, numerical data about trafficking causes and patterns in particular, as well as trafficking cases, is inadequate for social workers and law enforcement to effectively address it. One underlying reason for the scarcity of quantitative data on human trafficking is it is hard to detect and prosecute. This is especially true about labor trafficking even more so than sex trafficking. Different forms of exploitative labor such as poor working conditions can often tread a fine line between tough working conditions and labor trafficking, making it hard to prosecute. With sex trafficking, researchers are able to look at recruitment advertisements and physical signs of abuse among the many signs to detect the crime. One study shows that researchers at large have mainly aided criminal investigations for sex trafficking cases, leaving behind many labor trafficking ones. Though limited, qualitative data on trafficking is more publicly available. Qualitative data refers to non-statistical, largely anecdotal, text-based information that comes from trafficking case articles and reports. Since qualitative data is more available online, we used this type of data to train an algorithm to detect labor trafficking. The tool we built aims to help someone understand the signs of labor trafficking while also helping them to detect the crime. Our model predicts labor trafficking from text such as anecdotal reports and interviews with a 90% accuracy. It has an f-score of 91%, which is an alternative measurement of accuracy. This blog explains the labor trafficking tool in detail, looking at the best ways to use the tool, and the limitations it may have.
Machine learning can be used to identify patterns in data with speed and accuracy that humans cannot replicate. For this reason, human rights activists and researchers are working to apply machine learning to social justice issues, and to human trafficking in particular. An application of AI that has grown since the 1940s has been Natural Language Processing algorithms (NLP) to analyze text. These algorithms deal specifically with interpreting human language to derive new meaning. A lot of the information we have about human trafficking abuses are qualitative rather than quantitative. Due to this, we explored using NLP to work with existing trafficking data. The NLP algorithm we used was a Convolutional Neural Network (CNN), for supervised learning, which is defined as the calculation of the probability to detect yes/no. For our purposes, we used CNNs to detect the presence of trafficking (yes/no) from qualitative reports. By using a python library called spaCy, we used pieces of premade CNN code to help construct our trafficking tool. Other NLP algorithms that could be used include LSTM, BERT and XLNet, which are newer algorithms. All of these algorithms have different strengths in terms of understanding and making meaning of text. Given their novelty, it may require more work to understand and use them efficiently.
At large, the purpose of our trafficking tool is to detect the presence of trafficking from interviews in the general news wire and case reports from law enforcement. When a user types a situation into our algorithm, the algorithm will classify the situation as either a case of indicating trafficking or not indicating trafficking. As a secondary part to the tool, when a user types a situation, the algorithm creates a word cloud. This feature allows the user to visually identify some of the most frequent words in the text. Since labor trafficking and sex trafficking have different triggers and consequences, we decided to streamline our algorithm to detect labor trafficking only. Later we will discuss how the model can be improved or altered to address sex trafficking as well.
In this section I test the trafficking detection tool by pasting a migrant labor trafficking situation from the Human Trafficking Search website below. I only copied the first four paragraphs which deal with the conditions of the workers, since the rest of the article reveals that the scenario is a trafficking situation. Once I clicked the run button to the left of ‘example_text’ the output correctly stated ‘This indicated trafficking’.
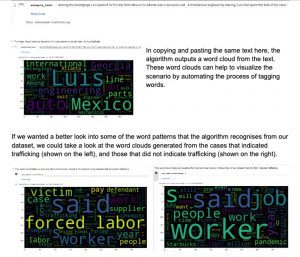
Perhaps one of the biggest differences between the reports that indicated trafficking as opposed to those that did not, would be that ‘forced labor’ is a common pattern in labor trafficking, instead of just identifying as a ‘worker’. However, many victims of trafficking may not even recognise that they are experiencing forced labor, which poses a limitation within our dataset. The dataset that our detection tool is trained on consists of approximately 25 labor trafficking cases and 25 non-trafficking labor cases. Of the 25 reports and articles indicating trafficking, many mention ‘forced labor’, so the algorithm strongly favors those words when trying to diagnose a case as indicating trafficking, and would likely fail to diagnose cases that do not have those or other more obvious keywords. Furthermore, the 90% accuracy of the detection tool comes from a 90% accuracy in detecting trafficking from the small 50-report-sample dataset. This dataset may provide much more clear-cut distinctions between trafficking and non-trafficking cases than all the labor reports that exist on the web, and as a result, all the labor reports that will be inputted into the algorithm. The CNN algorithm that was used to make the detection tool also focuses more on words rather than sentences. This means that it excels in recognising words as indicators of trafficking, but in a sea of words which it does not see as indicators, the keyword no longer is a strong enough of an indicator, and thus the model fails to detect trafficking.
In the example below, a section of a HTS story resource is inputted into the algorithm. The bolded words represent the output. When two sentences are inputted, the algorithm cannot detect trafficking. When the sentences with keywords are isolated, then only can the algorithm detect trafficking.

There are a few ways to remedy the limitations of the tool. As the tool presents concerns about how representative the dataset is of all the labor articles on the web, we could increase the dataset to include 100+ cases. This would also give the algorithm more indicators of trafficking and thus more ability to recognise patterns to detect trafficking. To make a detection tool for sex trafficking, one could replace my dataset with a dataset of 50 sex trafficking and 50 non-trafficking sexual service reports and import it into my algorithm. Given the wide range of new natural language processing algorithms, it would be worthwhile to try algorithms that are more sentence-oriented or combine multiple NLP algorithms. Even with those adjustments, the detection tool is not intended to be used as a sole indicator of trafficking. It is rather an exploratory tool that would allow data scientists, social workers, and other investigators of trafficking to help pinpoint trafficking by finding signs of trafficking. It merely opens up the possibility to classify trafficking through text with a machine learning model, with hopes that it can be further developed for accuracy, precision and detail.
The code for the detection tool can be found here . A csv file of the dataset used for the detection tool can be found here. Two HTS sources were used in the demonstrations including an article about migrant mexican engineers and a survivor of the Rwandan Genocide.